
1. Cloud Insight
- Cloud Insight는 네이버 클라우드 플랫폼이 제공하는 서비스들의 성능 지표를 통합 관리하고, 장애 발생 시 담당자에게 장애 정보를 신속히 전달할 수 있는 모니터링 서비스입니다.
- Cloud Insight가 제공하는 다양한 기능

1. 지표 조회 및 시각화
- NCP에서 제공하는 서비스들의 성능/운영 지표를 시각화하여 확인이 가능하며, 1시간, 6시간, 12시간, 1일, 1주 등의 특정 기간만 확인 할 수도 있다.
2. 사용자 대시보드 구성
- 서비스들을 카테고리로만 대시보드에 분류하여 많은 사용자들이 확인할때 불편함이 있기 때문에 목적/대상별 사용자 대시보드를 따로 만들어 원하는 항목을 빠르게 확인할 수 있다.
3. Event Rule 및 Event 관리
- 특정 상황에 대한 이벤트를 설정하여 해당 이벤트가 발생하면 담장자에게 SMS or Email을 보내도록 알람 설정을 할 수 있고 이벤트 발생과 연동하여 Cloud Functions이나 Auto Scaling 같은 기능이 작동하도록 할 수도 있다.
4. 유지 보수 일정 관리
- 알람은 이벤트 종료 전까지 주기적으로 보내도록 설정할 수 있는데 이러한 알람이 점검시에도 보내게 된다면 혼란이 생길 수도 있다.
- 유지 보수 일정을 설정하여 해당 기간에는 해당 자원에서 어떠한 이벤트가 발생하더라도 알람이 발생하지 않게 할 수 있다.
2. Dashboard
1. Service -> Management & Governance -> Cloud Insight를 클릭합니다.

2. Dashboard 탭에 기본적으로 만들어진 위젯들이 있습니다. Service Dashboard / Server(VPC)

3. Dashboard 목록이 나옵니다.
Cloud Insight에서 모니터링 가능한 서비스들은 서비스가 생성되어 있다면 이렇게 기본 Dashboard가 생성되어 자동으로 모니터링을 시작합니다.

4. 기본 생성된 Dashboard에서도 위젯 데이터 변경을 통해 원하는 자원만 모니터링 할 수 있지만 여러 사용자들이 볼때마다 항목을 바꿔서 봐야하는 번거로움이 있습니다.

5. 그러니 사용자별로 원하는 항목을 모니터링 할 수 있게 대시보드를 새로 생성해보겠습니다.
대시보드 생성을 클릭합니다.

6. 저는 Web01,02 서버를 모니터링 하고 싶어서 Web으로 생성하겠습니다.

7. Dashboard가 생성되었지만 위젯이 하나도 없습니다. 위젯 추가를 클릭합니다.
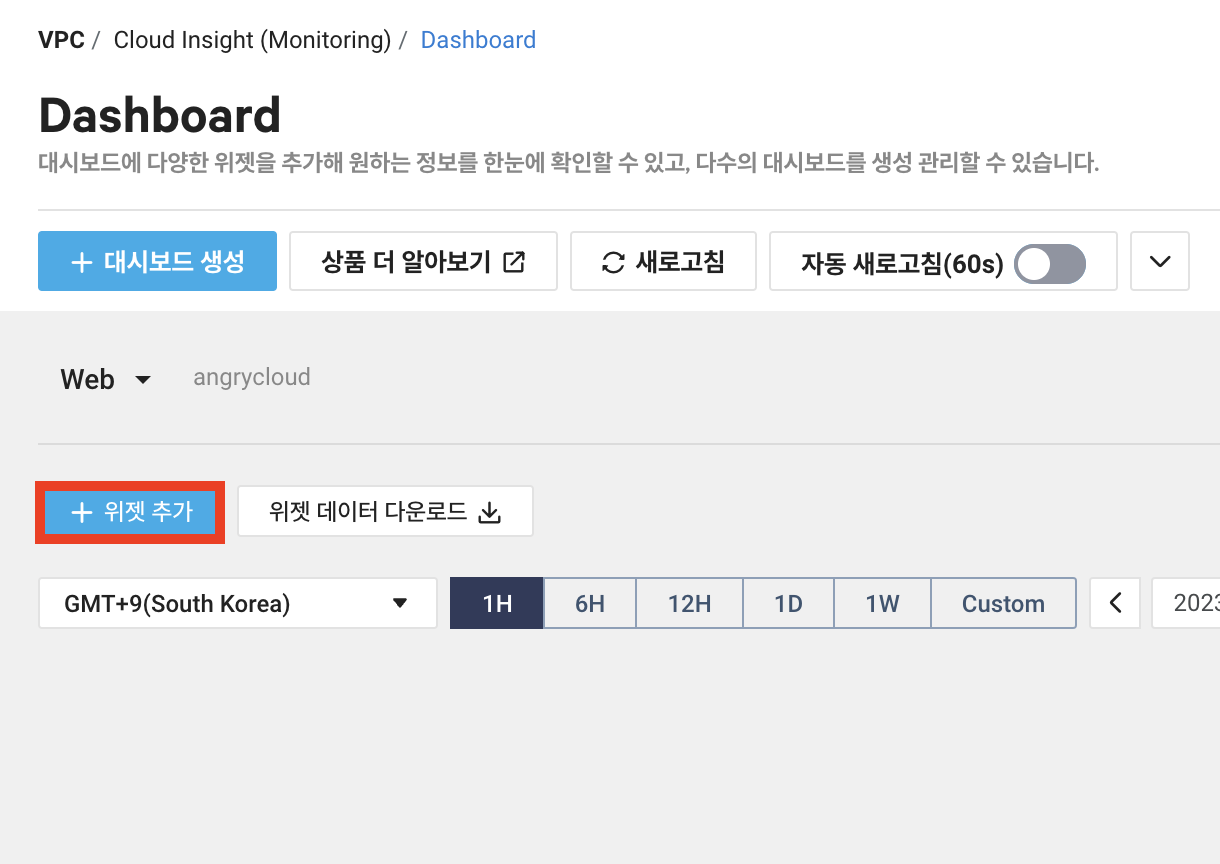
8. 위젯의 종류를 선택할 수 있습니다. 전 원하는 이름과 위젯 종류를 선택하고 다음을 클릭합니다.

9. Product Type에는 생성되어 있는 서비스 타입들이 뜰텐데 Server를 모니터링하고 싶은거니 Server(VPC)를 선택합니다.
Target은 원하는 서버들을 선택하여 만든 그룹과 오토스케일링 그룹, 보유 리소스 전체(1개만 선택) 가능 3가지 타입이 있습니다.
보유 리소스는 서버를 1개만 선택 가능하고 오토스케일링은 생성 안했으니 그룹을 생성하여 Web01과 Web02를 추가하겠습니다.

10. 그룹 이름과 설명을 정하고, 원하는 서버를 선택 후 ▽를 클릭합니다.

11. 선택한 감시 대상에 서버가 추가된 것을 확인하고 생성을 클릭합니다.

12. 그룹 목록에 방금 생성한 타겟 그룹이 추가되었습니다.
타겟 그룹을 선택해주고 메트릭은 cpu 사용률을 선택합니다.
타겟 그룹 선택 -> 전체 메트릭 -> SERVER -> avg_cpu_user_rto -> 선택 항목 추가를 클릭합니다.
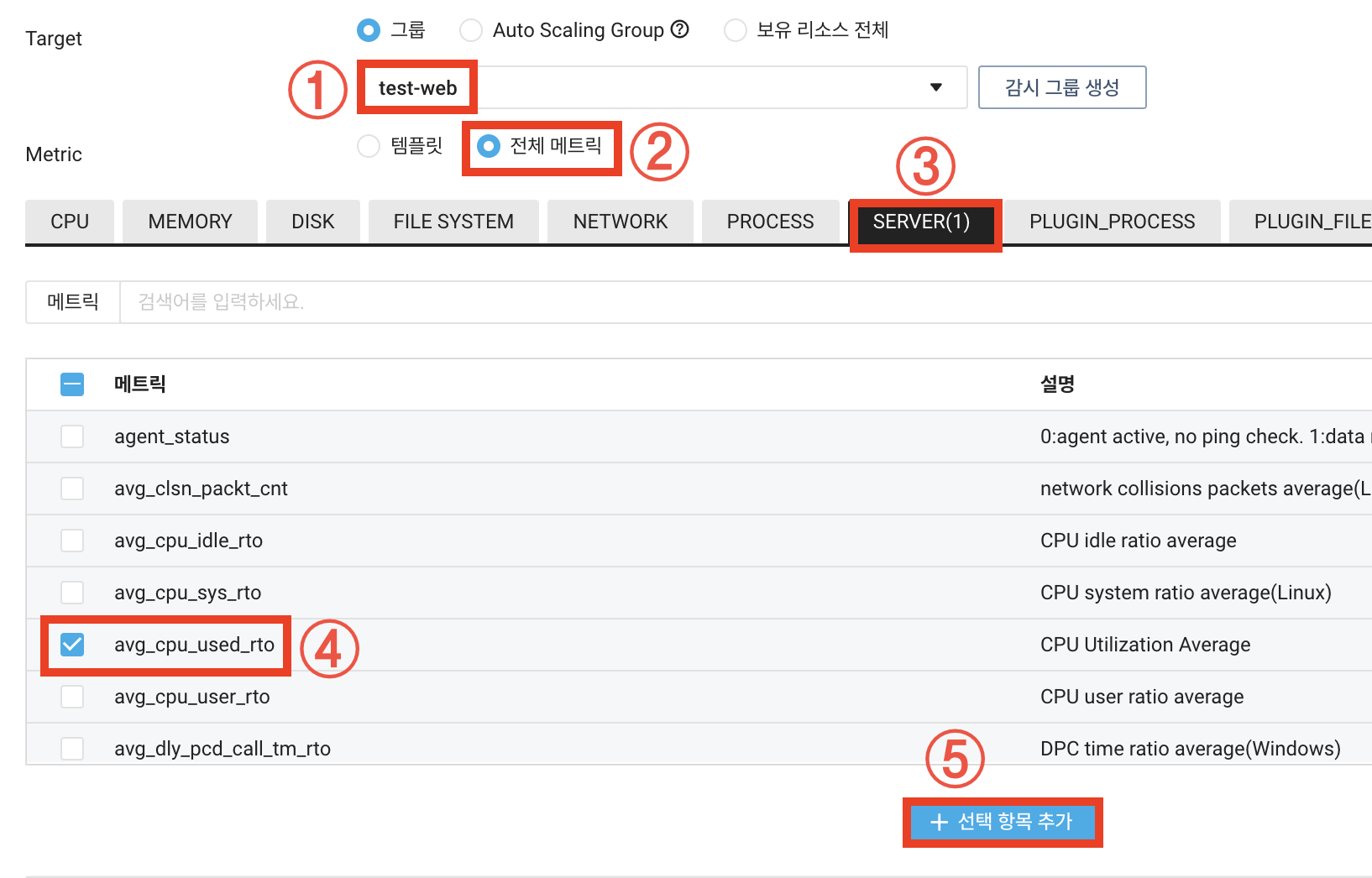
13. 감시 대상과 메트릭이 제대로 설정되었는지 확인하고 조회 주기는 빠른 확일을 위해 1분으로 바꾸고 다음을 클릭합니다.
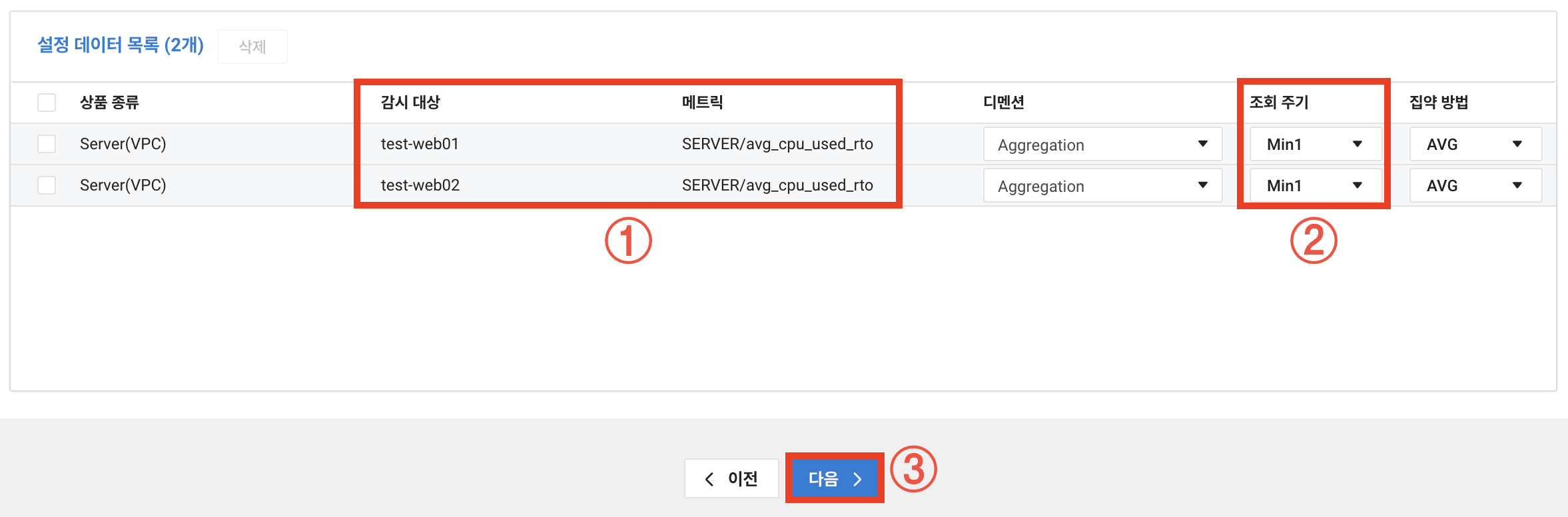
14. 메트릭이 수집되고 있는 것이 보입니다.
별칭이 너무 긴거 같으니 적당히 줄여주고 다음을 클릭하겠습니다.
변경 전
{resourceName}, SERVER/avg_cpu_used_rto
변경 후
{resourceName}, cpu_used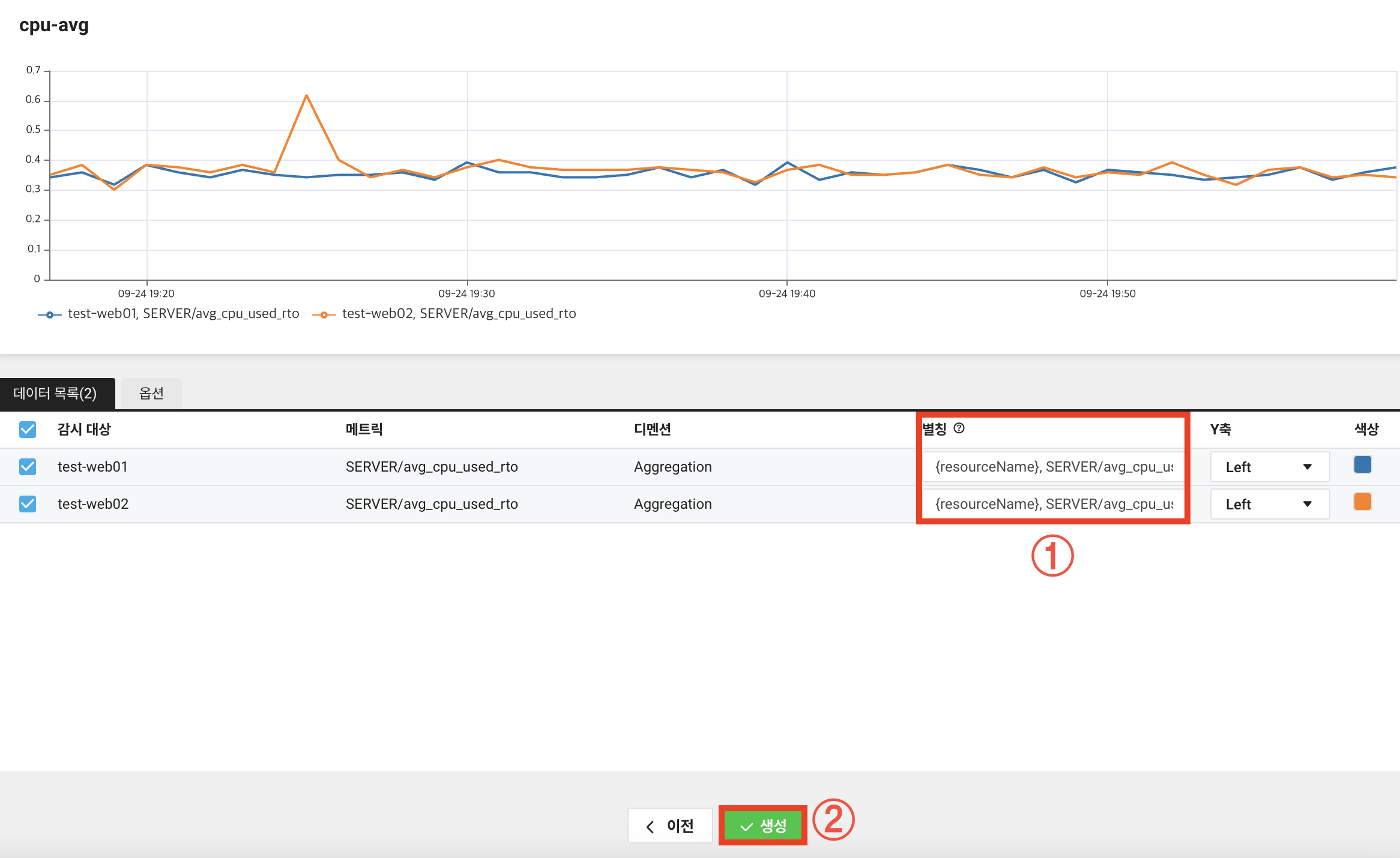
15. 이제 Web 대시보드에서 web01과 02 서버의 cpu 사용률 모니터링이 가능해졌습니다.
그러나 대시보드를 24시간 모니터링하고 있을 수는 없겠죠.
이제 Cloud Insight에 이벤트를 설정하고 해당 이벤트 발생시 담당자에게 알람이 가도록 해보겠습니다.

3. Event Rule
1. Configuration -> Event Rule -> Event Rules 생성을 클릭합니다.

2. 대시보드때와 마찬가지고 현재 생성되어 있는 서비스 유형들만 목록에 뜹니다.
Sever(VPC)를 선택하고 다음을 클릭합니다.

3. 아까 생성했던 감시 대상이 보입니다.
선택하고 다음을 클릭합니다.

4. 이제 감시 대상들의 어떤걸 감시할 것인지를 정해야 합니다.
템플릿 생성을 클릭합니다.

5. cpu 사용률에 대한 알람을 받을 예정이니 템플릿 이름과 설명, 메트릭을 cpu 사용률로 선택하고 다음을 클릭합니다.

6. 조건을 50보다 높을 시로 설정하고 저장을 클릭합니다.

7. 템플릿이 생성되었습니다.
템플릿을 선택하고 다음을 클릭합니다.

8. 설정한 이벤트 발생 시 수행할 액션을 설정하는 창이 떴습니다.
알람 메시지 발송, Intergration, Cloud Functions, Auto Scaling을 설정할 수 있으며, 지금은 알람 메시지만 설정해보겠습니다.
Certificate Manager 글에서 생성했던 웹 관리자를 선택.
이벤트 발생 시 이벤트 종료까지 반복적으로 알람을 보내게 해주는 리마인드 주기는 5분으로, 이벤트 종료시 종료 메시지를 보내주는 종료 알림은 ON 하겠습니다.

9. 마지막으로 룰의 이름과 설명을 적고 생성을 클릭합니다.
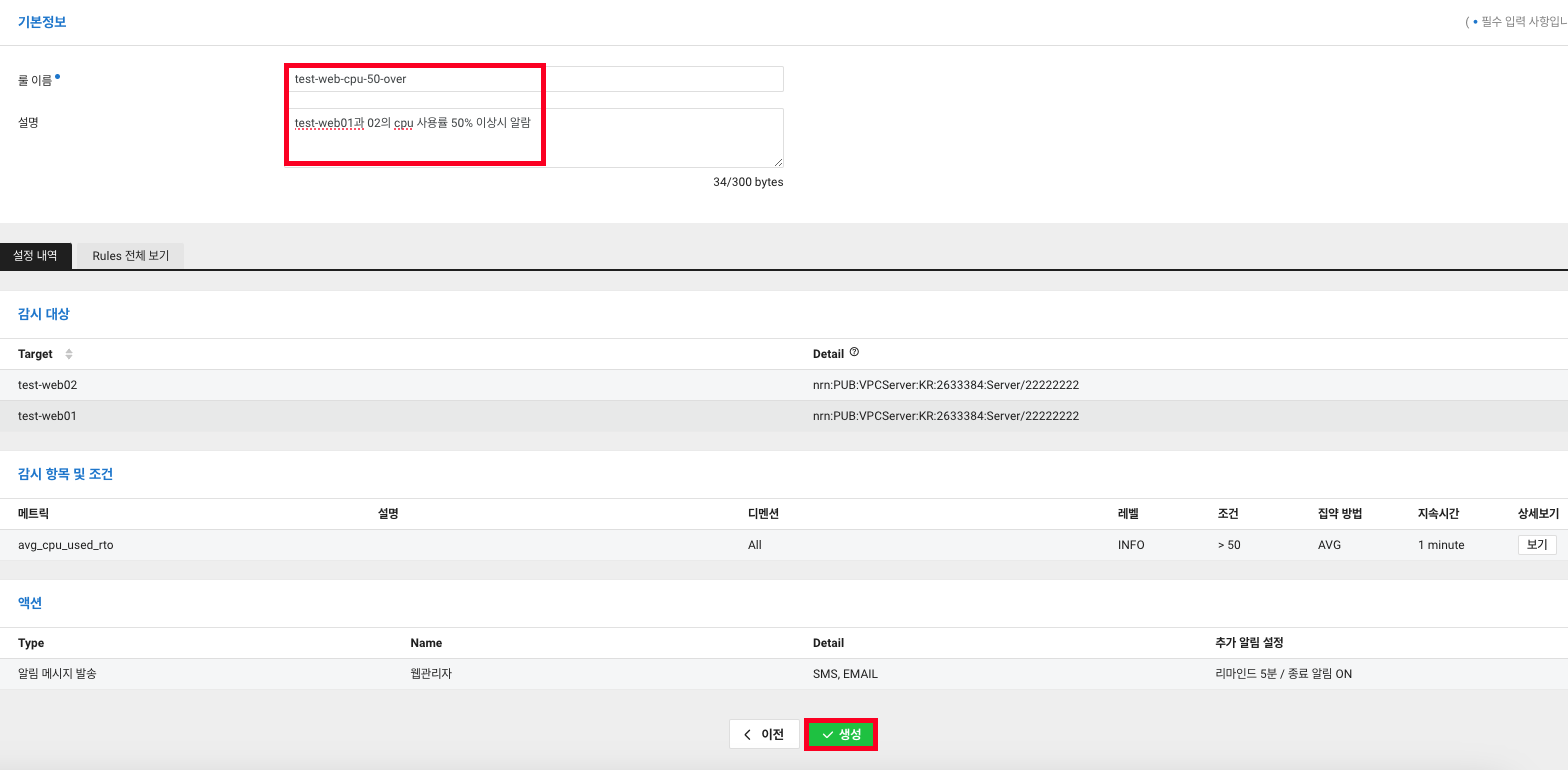
10. 이벤트 룰이 생성되었습니다.
이제 서버에서 부하를 주고 알람이 오는걸 확인해보겠습니다.

11. cpu 사용률 테스트를 위해 stress를 설치합니다.
stress 명령어는 CPU, 메모리, 디스크 등 시스템 자원에 부하를 가하는 도구입니다.
이를 사용하여 시스템이 얼마나 튼튼하게 동작하는지 테스트하거나 성능 문제를 진단하는 데 사용할 수 있습니다.
yum -y install stress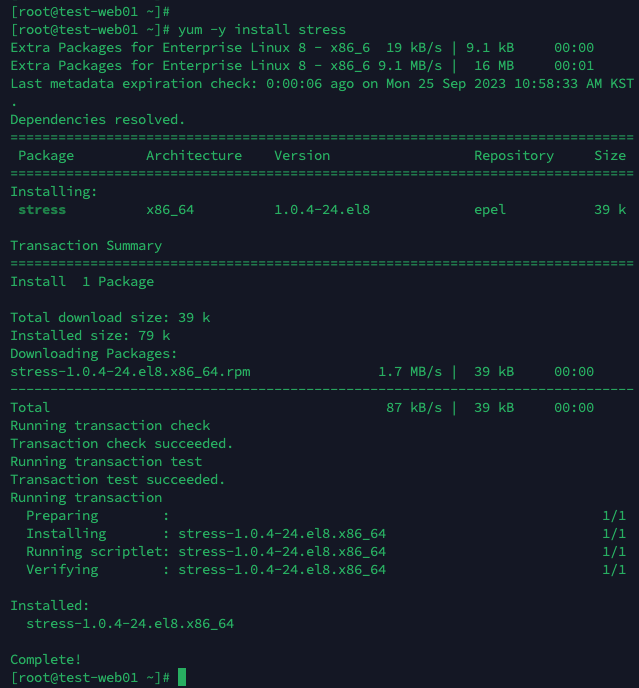
12. 서버 사양에 맞게 cpu에 부하를 줘보겠습니다.
제가 쓰는 서버는 2코어니 2코어 전부에 부담을 주겠습니다.
# -c 코어수 : 지정된 코어 갯수에 100% 부하
stress -c 2
13. top 명령어로 확인해보면 cpu 사용률이 100%까지 올라갔습니다.
top
14. 이번에는 Cloud Insight에서 생성했던 대시보드로 가보겠습니다..
cpu에 부하를 준 web01 서버의 그래프가 100까지 올라간게 보입니다.

15. SMS와 E-Mail로 알람이 정상적으로 오고 있습니다.

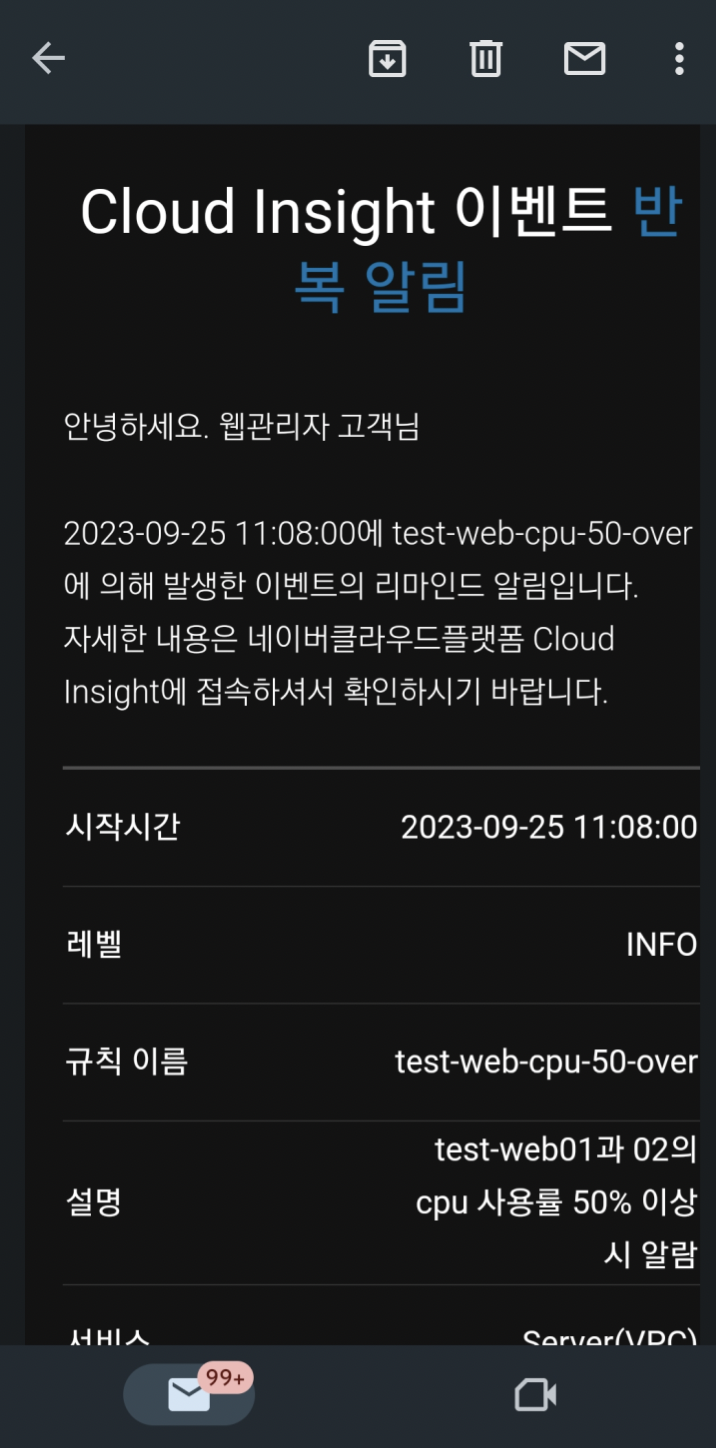
16. 알람이 오는 걸 확있했다면 서버에서 stress를 kill 해줍니다.
ps -ef | grep stress
kill -9 PID
17. 기다리다보면 대시보드에서도 사용률이 내려가는게 보입니다.

18. cpu 사용률이 떨어져 이벤트 종료 알람이 발생하는 것도 확인합니다.


4. Planned Maintenance
1. 왼쪽 Cloud Insight 메뉴에서 Planned Maintenance로 들어가면 달력이 보입니다.

2. 제목과 설명을 써주고 작업시간을 클릭합니다.
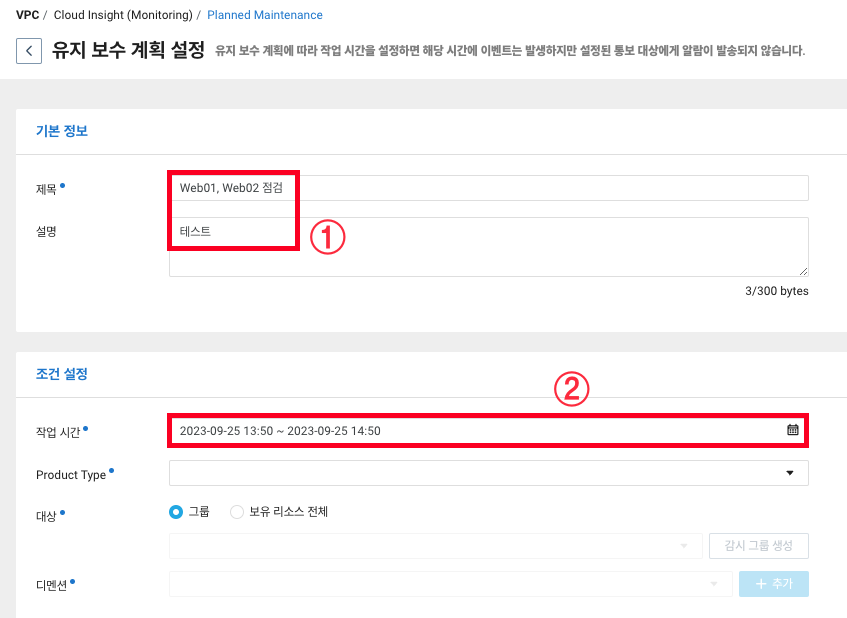
3. 점검 시간과 날짜를 지정할 수 있습니다.
저는 간단히 테스트 하는거니 당일 14:30~14:50까지 20분간만 지정하겠습니다.
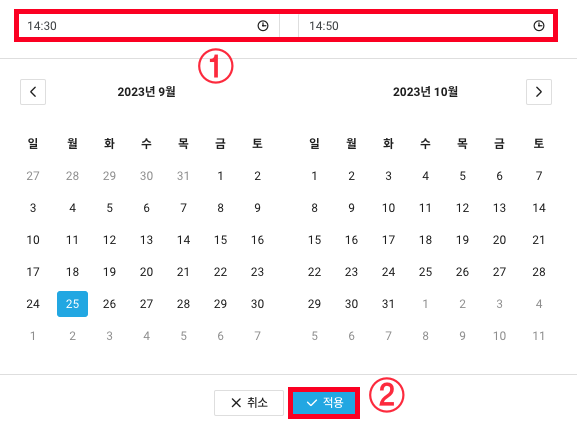
4. Server 대상이니 Product Type는 Server(VPC)를 선택하고 대상은 앞서 생성했던 test-web 그룹(web01,02) 선택. 디멘션은 Server/default를 선택 후 추가를 클릭합니다.

5. 목록이 추가된걸 확인하고 완료를 클릭합니다.

6. 달력에 일정이 추가되었습니다.

7. 다시 서버에 부하를 주고 점검시간에 알람이 오는지 확인합니다.

8. 점검시간 내에 부하가 걸려도 알람이 오지 않는 것을 확인할 수 있습니다.


Cloud Insight로 NCP 서비스를 모니터링하고 이벤트 발생 시 알람을 보내도록 해보았습니다.
다음 글에서는 이벤트 발생 시 서버를 자동으로 추가하거나 반납하는 Auto Scaling을 해보도록 하겠습니다.
Auto Scaling : https://angrycloud.tistory.com/34